Google Cloud | Data Engineering
Mastering the Google Cloud Professional Data Engineer Exam in 2023: Strategies and Resources
This article offers tips and resources for mastering the Google Cloud Professional Data Engineer exam in 2023.

Disclaimer
This article is intended to provide general information and guidance for individuals preparing for the Google Cloud Professional Data Engineer exam. It is not a comprehensive study guide and should not be relied upon as a sole source of information for preparing for the exam. The content of the exam may change over time and it is the responsibility of the individual to ensure that they are adequately prepared based on the most current exam objectives and requirements. The strategies and resources discussed in this article are intended to supplement, but not replace, the official exam guide and other study materials provided by Google.
In 2023, Data Engineering is likely to continue to be an important field as the amount of data being generated by businesses and organizations is expected to continue to grow. Data engineers will be responsible for building and maintaining the pipelines that allow this data to be collected, stored, and processed, enabling organizations to make informed decisions based on data-driven insights.
Obtaining the Google Cloud Professional Data Engineer certification can be beneficial for a number of reasons:
- Demonstrate your skills and knowledge: The certification is a way to demonstrate to potential employers or clients that you have the skills and knowledge required to work with the Google Cloud Platform as a data engineer.
- Enhance your career prospects: Many employers value certifications and may be more likely to hire or promote individuals who have them. Obtaining the Google Cloud Professional Data Engineer certification can therefore improve your career prospects.
- Stay current with industry trends: The certification exam covers the latest trends and best practices in the field of data engineering, so obtaining the certification can help you stay up-to-date with developments in the industry.
- Increase your credibility: The certification is an objective third-party validation of your skills and knowledge, which can increase your credibility with employers and clients.
- Enhance your earning potential: Data engineers with certifications may be able to command higher salaries or consulting rates due to their demonstrated expertise.
Overall, the Google Cloud Professional Data Engineer certification can be a valuable asset for individuals working in the field of data engineering.
Contents
- What is required to be known before pursuing the certification?
- Designing data processing systems
- Building and operationalizing data processing systems
- Operationalizing machine learning models
- Ensuring solution quality
- Courses and Books
- Practice Tests
- Conclusion
- References
What is required to be known before pursuing the certification?
The Google Cloud recommends at least 3 years of experience to take the exam. you need to answer 50 multiple-choice and multiple-select questions in 120 minutes and costs 200$.
The certification exam tests your knowledge and experience with GCP services/tools/applications by giving you suitable scenarios. To beat this one needs to have an understanding and working experience of the said tools/applications.
The official exam guide has divided the contents of the exam into the following four sections.
- Designing data processing systems
- Building and operationalizing data processing systems
- Operationalizing machine learning models
- Ensuring solution quality
Mastering the vast array of tools and applications offered by Google Cloud Platform (GCP) is no easy task. In this article, The article covers strategies and resources that aided me in successfully passing the GCP Professional Data Engineer exam.
- Review the exam guide and become familiar with the objectives and skills tested.
- Gain hands-on experience with the Google Cloud Platform.
- Use study materials and practice exams to supplement your learning.
- Stay current with industry trends and developments.
- Create a study plan and stick to it to stay on track with your preparation.
- Consider joining a study group or finding a study partner to help you prepare for the exam.
- Be sure to allocate sufficient time and resources for studying and preparing for the exam.
- Take advantage of resources such as forums and online communities to get support and advice from other professionals preparing for the exam.
Designing data processing systems
The section covers different essential google cloud data processing services. I have found the following services PubSub, Dataflow, Apache Beam Concepts, Dataproc, Apache Kafka Vs PubSub, Storage Transfer service, and Transfer Appliance are often covered in the exam.

Dataproc
Dataproc is google’s fully managed service and is highly scalable for running Apache spark, Apache Hadoop, Apache Flink, Presto, and other open-source frameworks. It can be used to modernize data lakes, and ETL operations, and secure data science operations at scale.
Key Points:
- Use Google Cloud storage as persistent storage needs rather than using Hadoop-compatible file systems and ensure the bucket and cluster are in the same region.
- while autoscaling, preferably scale secondary worker nodes. Use Prempteble Virtual Machines(PVMs) which are highly affordable, short-lived instances suitable for batch and fault tolerant jobs.
- Using a high percentage of PVMs may lead to failed jobs or other related issues, Google recommends using no more than 30% PVMs for secondary worker instances.
- Rigorously test your tolerant torrent jobs which are using PVMs before moving them to the production environment.
- Graceful decommission should ideally be set to be longer than the longest-running job on the cluster to cut the unnecessary cost.
Pubsub
Cloud Pubsub is a fully managed, asynchronous, and scalable messaging service that decouples services producing messages and services processing the messages with millisecond latency.
Key Points:
- Leverage schema on the topics to uniform schema throughout the messages.
- Leverage “Cloud Monitoring” to analyze different metrics related to pubsub and use alerting to monitor topics and subscriptions.
- Messages are persisted in a message store until they’s are acknowledged by subscribers.
Dataflow
Dataflow is a serverless batch and stream processing service that is reliable, horizontally scalable, fault-tolerant, and consistent. It is often used for data preparation and ETL operations.
Key Points:
- It can read data from multiple resources and can trigger multiple cloud functions in parallel to do multiple sinks in a distributed fashion.
- Leverage Cloud Dataflow connector for cloud Bigtable to use Bigtable in dataflow pipelines.
- Study windowing techniques Tumbling, Hopping, Session, and Single global windows.
- By default single global window is applied irrespective of the pipeline processing type(Batch or Stream). It is recommended to use non-global windows for stream data processing.
- Study Different types of triggers Time-based, Data-driven, and Composite triggers.
Here is one of the best documentation that helped me to learn and revise the Apache Beam concepts.
Data fusion
Cloud Data fusion is a fully managed, native data processing service at scale. It’s built on open-source core CDAP for pipeline portability and a code-free service that lets you build EL/ET and ETL solutions at scale. It has 150+ preconfigured connectors and transformations.
Key Points:
- Best suited for quick development and code-free solution and helps to avoid technical bottlenecks and code maintenance.
- It has built-in features such as end-to-end data lineage and data protection services.
Data Migration Services
Cloud Transfer Service helps to send data from on-premise to the cloud and cloud to cloud storage.
Cloud Transfer Appliance is a service that handles the one-time transfer of petabytes of data from one location to another on a highly secure disk.
Building and operationalizing data processing systems
Studying Bigquery, Cloud SQL, Cloud Spanner, Cloud Storage, and cloud Datastore documentation helps a lot to understand fine details that are often asked in the exam.
Google Cloud offers different data storage services/applications, here is a diagram that shares a quick overview of the mentioned services/applications.
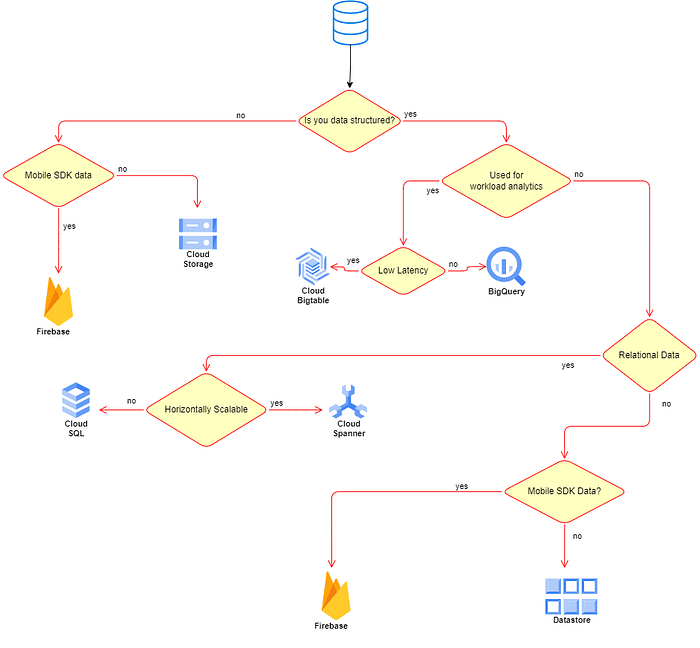
Cloud Storage
It’s a managed storage system that stores data in blobs and virtually provides unlimited storage.
- Standard — No minimum storage and retrieval fees.
- Nearline — Minimum storage for 30 days and incur retrieval fees.
- Coldline — Minimum storage for 90 days and incur retrieval fees.
- Archive — Minimum storage for 365 days and incur retrieval fees.
The data stored is encrypted by default at rest and Google Cloud provided different encryption options such as Customer Supplied Encryption Keys, and Customer Managed Encryption Keys and also supports Client-side encryption.
Cloud BigTable
Cloud BigTable is a no-SQL database service with large analytical and operational workloads. It provides high throughput, no ops, and low latency. It leverages Google’s internal Colossus storage system.
Key Points:
- It’s not suitable for relational data.
- It is suitable for data on a petabyte scale and it’s not efficient storage for data less than 1 Tera Byte(TB).
- BigTable is sparse storage and it has a limit of 1000 tables per instance. it recommends having far fewer tables and having too many small tables is an anti-pattern.
- Put related columns in a column family with a short meaning full name and you can create up to 100 column families per table.
- Design row keys depending on how you intend to query the data, keep your row keys short(4KB or less) and Keep them in a human-readable format that starts with a common value and ends with a granular value.
- To increase read throughput and write throughput create read replicas and add nodes to the cluster.
- Use Key Visualizer to detect the hotspots and use separate app profiles for each workload.
- For latency-sensitive applications, google recommends that you keep storage utilization per node below 60%.
BigQuery
BigQuery is a fully managed, serverless, scalable, and analytical data warehouse. It can connect to Google Cloud Storage(GCS), BigTable, and Google Drive. It can import data from CSV, JSON, AVRO, and datastore backups. The alternative for this service is Hadoop with Hive. By default it expects all data to be in UTF-8 encoding and also supports Geospatial and ML functionality.
Key Points:
- It cannot upload/import multiple files at the same time and file size greater than 10MB and can’t load files in SQL format.
- Use partitioning and clustering to increase query performance and reduce costs.
- Don’t use LIMIT on tables with large data instead select the columns that you need.
- It loads batch data for free but streaming data increases the cost.
- Denormalize the data as much as possible to optimize the query performance and to make queries simpler.
- Use pseudo columns(_PARTITIONTIME) to retrieve the partition from a table.
- Use window functions to increase efficiency and reduce the complexity of the queries.
- Avoid self-joins and cross-joins that generate more output columns than input columns.
- Use batch update to update multiple rows instead of a point-in-time update.
- The Security can be applied on the dataset level, not on tables. Leverage authorized views to share data of particular data without sharing access to underlying tables.
- Use flat-rate pricing to reduce the cost if you’re using on-demand pricing.
- BigQuery does billing based on storage, querying, and streaming inputs.
Cloud SQL
Cloud SQL is a fully managed relational database that supports MySQL, SQL Server, and PostgreSQL. It supports low latency and can store up to 30TB. It supports the import/export of databases using mysqldump and also the import/export of CSV files.
- It supports High Availability and Failover by switching to the standby instance automatically.
- It supports replication and read replicas to reduce the load on the primary instance by offloading the read requests to the read replicas.
Cloud Spanner
Cloud Spanner is a fully managed, horizontally scaling, distributed relational database. It supports high availability and zero downtime on ACID transactions globally.
- It provides strong consistency including strongly consistent secondary indices.
- It supports interleaved tables.
- It optimizes the performance by sharding the data based on the load and size of the data automatically.
- It provides low latency and automatic replication.
- It supports both regional and multi-regional instances.
Operationalizing machine learning models
Though the ML-related questions in the exam are fewer compared to other services. I found them easy to answer and straightforward compared to others and can be answered by having a limited understanding of the following services and concepts.
The questions revolve around the GCP Services related to ML such as SparkML, BigQueryML, DialougeFlow (Chatbot), AutoML, Natural Language API, Vertex AI, DataLab, and KubeFlow.
The section covers different following Machine Learning concepts.
- Supervised learning
- Unsupervised learning
- Recommendation engines
- Neural Networks
- Optimizing ML models(Overfitting, underfitting, e.t.c)
- Hardware acceleration
Here is the crash course that I found useful while preparing for the exam.
Ensuring solution quality
Google Cloud’s Identity and Access Management (IAM) system is used to enforce necessary restrictions depending on the role and task of a group. There are three basic roles for every service Owner, Editor, and Viewer and there are predefined roles for each service, custom roles can be created when there is a need.
Use Cloud Monitoring(stack driver monitoring) and Cloud Logging to analyze, monitor, and alert on log data and events. Cloud Logging retains the following logs for 400 days and the logs other than these are retained for 30 days.
I have found the documentation helps to understand how policies and roles work throughout the GCP organization hierarchy.
Key Points:
- Use the security principle of least privilege to grant IAM roles. i.e., only give the least amount of access necessary to your resources.
- Grant roles to specific google groups instead of individual users whenever possible.
- Use service accounts while accessing the GCP services instead of individual user accounts.
- Billing Access can be provided to a project or group of projects without granting access to the underlying data/content.
Data Protection
Data loss prevention API is a fully managed scalable service that identifies the sensitive data across the cloud storage services(Cloud Storage, BigQuery, etc.). It also has the ability to mask with or without retaining the data format.
Data Catalog is a fully managed scalable metadata management service that helps to search for insightful data, understand data, take data-driven decisions, and also helps to govern the data.
Check out different legal compliance for data security. [Health Insurance Portability and Accountability Act (HIPAA), Children’s Online Privacy Protection Act (COPPA), FedRAMP, General Data Protection Regulation (GDPR)]
Courses and Books
Here are the courses and books that I found resourceful to master the GCP Data Engineering Certification.
- If you are an aspirant with less hands-on experience with GCP. The Data Engineering Learning Path is quite effective to gain knowledge and hands-on experience.
2. For a quick overview of the data engineering learning path for experienced individuals, consider going through “Google Cloud Professional Data Engineer: Get Certified 2022”.
The following books by Dan Sullivan and Priyanka Vergadia provide helpful insights into the various services and concepts covered on the GCP data engineering certification exam.
Practice Tests
Practice tests can be an important tool to familiarize yourself with the exam format, identify your area of weakness, increase your confidence and improve your test-taking strategies.
- The Official Google Cloud Certified Professional Data Engineer Study Guide book offers practice questions after each section.
- Sample questions from the Google Professional Data Engineer site.
- Dan Sullivan’s Google Cloud Professional Data Engineer Practice Tests include two simulated exams that follow the same format as the actual certification exam.
Conclusion
Preparing for the Google Cloud Professional Data Engineer exam requires a combination of knowledge, skills, and strategy. By reviewing the exam guide and becoming familiar with the objectives and skills tested, taking online courses or attending in-person training, gaining hands-on experience with the Google Cloud Platform, and using study materials and practice exams to supplement your learning, you can increase your chances of success on the exam.
With the right approach and the right resources, you can master the Google Cloud Professional Data Engineer exam in 2023.
Long Live and Prosper …🖖
